File Uploads
As indicated in this section, the schema for insured individuals within the Osigu platform is extensive to provide flexibility for various business models and payer-specific plan and policy configurations.
Each entity in Osigu's data model has an equivalent CSV file that can be transferred and processed.
The payer must create each file to be uploaded and compress it into a zip file, which is then transferred using the method defined during the integration phase (e.g., NFS, SFTP).
Data Structure
The following diagram outlines the data structure and corresponding CSV files that can be received. Not all files in this diagram are typically used or required in a given integration.
The diagram highlights the structures commonly used in integrations.
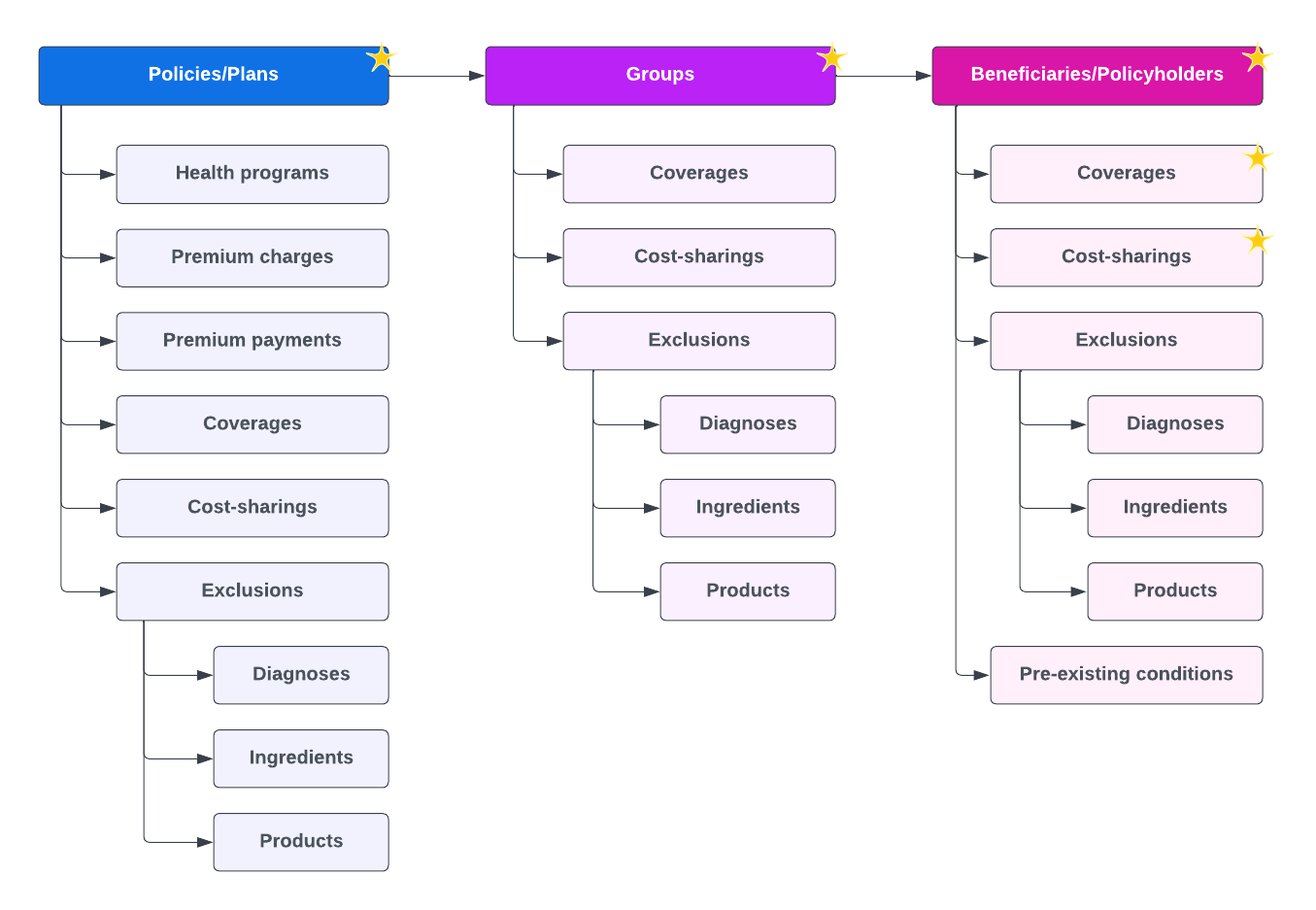
The schema allows configurations at three levels:
- Policy/Plan: Settings affect all groups and insured individuals within a policy.
- Group: Settings affect only insured individuals within a specific group.
- Individual: Settings apply to a single insured individual.
Payers can configure shared costs, exclusions, and coverages at any combination of these levels. If configured at multiple levels, the system accumulates these configurations, applying all relevant settings.
Connection and Transfer
Files can be uploaded via the SFTP protocol to the following address:
sftp.plans.osigu.com.
Osigu will provide a unique user and certificate for authentication for each environment (Production and Sandbox).
Upon authentication, the root directory will include the following structure:
- input: Place files to upload to this directory.
- output: The system will place processing results in this directory.
Upload File Naming Convention
The CSV files must be compressed into a single archive in zip, gzip, or rar format and uploaded to the input directory.
Each file must have a unique name to prevent conflicts during processing. The recommended naming structure is:
<country_code>-<name>_<timestamp>.<zip|gzip|rar>
Example:
us-umbrellacorp-20210110T060001.zip
After processing, a *.log file will be placed in the output directory with a detailed result, showing successfully processed lines and those with errors. This log file will have the same name as the original archive.
Processing Workflow
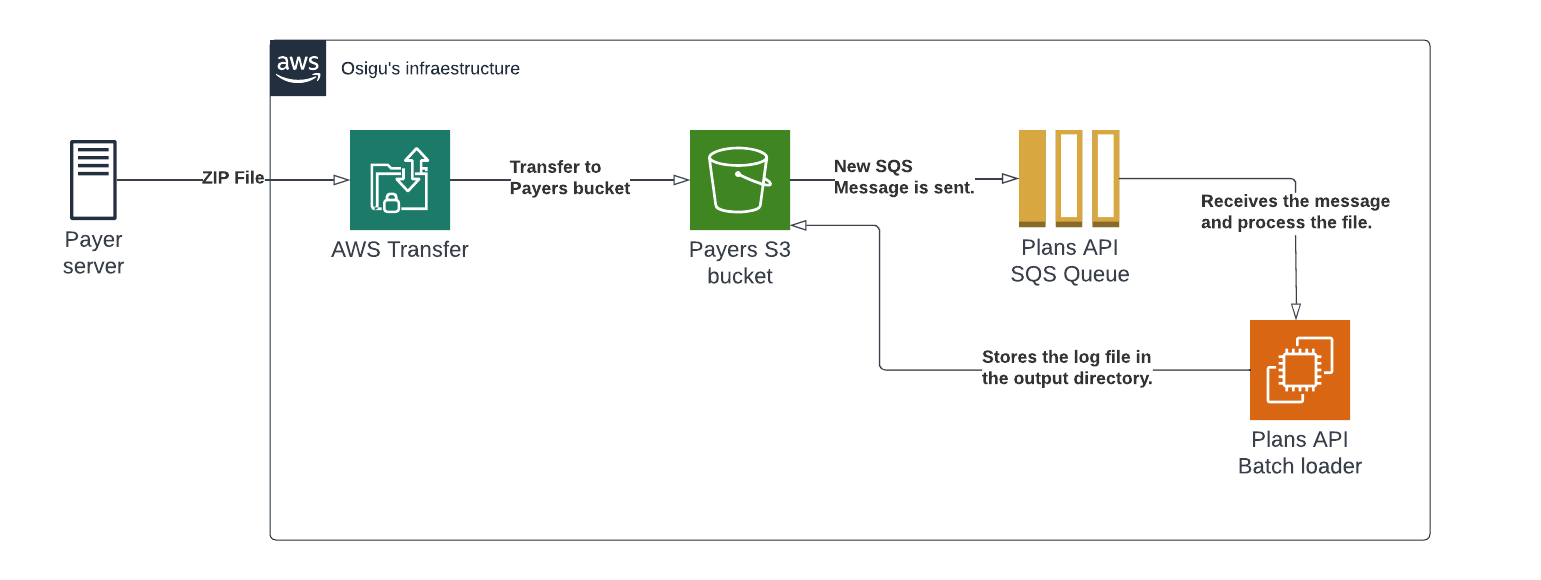
The diagram above illustrates the workflow triggered when a *.zip file is placed in the input directory.
Upon detecting a new file, the system emits an event to the Plans API queue, which manages plans and insured information for the payer. Processing begins immediately after the file is detected.
CSV Files
The archive must contain at least one CSV file. The system does not expect all files to be included but processes only the ones provided.
While sending the same files regularly is common practice, the system verifies each line for changes since the last upload and determines whether to update, insert, or delete records.
ImportantRecords not included in subsequent uploads will be considered removed and will no longer be available for future authorizations.
Requirements for CSV Files
- Files must be UTF-8 encoded to ensure special characters display correctly on the platform.
- The first line must always contain headers.
- Fields must be comma-separated (
,). - All text values must be enclosed in double quotes (
"), allowing commas to be used within fields like addresses or names. - Double quotes inside a value must be escaped using a backslash (
\).
Data Types
String
- Text values enclosed in double quotes (
"). - Maximum length is indicated in brackets
[ ].
Timestamp
- ISO 8601 formatted date-time strings, including timezone information.
- Example for January 1, 2022, at midnight in GMT-6:
"2022-01-01T06:00:00.000Z"(UTC)"2022-01-01T00:00:00.000-06:00"(America/Central)"2022-01-01T04:00:00.000+02:00"(Europe/Spain)
Enum
- String values from a predefined list (e.g.,
(MALE | FEMALE | NOT_KNOWN)).
Boolean
- Values
"true"or"false"enclosed in double quotes.
Integer
- Whole numbers are enclosed in double quotes, ranging from -2,147,483,648 to +2,147,483,647.
Decimal
- Numbers with fractional values. Precision and scale are defined as
Decimal(precision, scale).
Handling Excess PrecisionIf a number exceeds the allowed precision, the fractional part is truncated. For example:
3210987654321.555888is stored as3210987654321.55.
File Processors
Osigu provides 27 processors, allowing the payer to decide which files to use based on their data and operational requirements.
Configurations can occur at multiple levels (Policy/Plan, Group, Individual), and the system applies these configurations cumulatively.
Refer to the table below for available processors and their respective documentation:
| # | File Name | Description |
|---|---|---|
| 1 | v2_policies.csv | Contains basic plan/policy information. Required for the initial upload. |
| 2 | v2_disease_groups.csv | Lists ICD-10 codes related to a medical condition. Optional. |
| 3 | v2_po_health_programs.csv | Associates health programs with a plan/policy. |
| 4 | v2_po_premium_charges.csv | Indicates additional charges to the policy premium. Informational only. |
| 5 | v2_po_premium_payments.csv | Lists premium payments for each policy. Informational only. |
| 6 | v2_po_costs_sharings.csv | Configures copayments and coinsurance at the policy level. |
| 7 | v2_po_coverages.csv | Specifies coverages available for authorization generation at the policy level. |
| 8 | v2_po_exclusions_by_diagnoses.csv | Lists of ICD-10 diagnoses excluded from coverage at the policy level. |
| 9 | v2_po_exclusions_by_ingredient.csv | Lists of active ingredients are excluded from coverage at the policy level. |
| 10 | v2_po_exclusions_by_diag_tests.csv | Lists excluded diagnostic tests at the policy level. |
| 11 | v2_po_max_benefits_per_disease.csv | Specifies maximum benefits per disease group at the policy level. |
| 12 | v2_groups.csv | Contains groups within a policy. Required for initial uploads. |
| 13 | v2_gr_costs_sharings.csv | Configures copayments and coinsurance at the group level. |
| 14 | v2_gr_coverages.csv | Specifies coverages available for authorization generation at the group level. |
| 15 | v2_gr_exclusions_by_diagnoses.csv | Lists of ICD-10 diagnoses were excluded from coverage at the group level. |
| 16 | v2_gr_exclusions_by_ingredient.csv | Lists of active ingredients are excluded from coverage at the group level. |
| 17 | v2_gr_exclusions_by_diag_tests.csv | Lists excluded diagnostic tests at the group level. |
| 18 | v2_gr_max_benefits_per_disease.csv | Specifies maximum benefits per disease group at the group level. |
| 19 | v2_policyholders.csv | Lists insured individuals to be included in a policy and group. Required for initial uploads. |
| 20 | v2_certificate_costs_sharings.csv | Specifies shared costs applicable at the certificate level. |
| 21 | v2_ph_coverages.csv | Configures coverages available for an individual insured. |
| 22 | v2_ph_exclusions_by_diagnoses.csv | Lists ICD-10 diagnoses excluded from coverage for an individual insured. |
| 23 | v2_ph_exclusions_by_ingredient.csv | Lists active ingredients excluded from coverage for an individual insured. |
| 24 | v2_ph_exclusions_by_diag_tests.csv | Lists excluded diagnostic tests for an individual insured. |
| 25 | v2_ph_max_benefits_per_disease.csv | Specifies maximum benefits per disease group for an individual insured. |
| 26 | v2_ph_pre_existing_conditions.csv | Lists ICD-10 codes for pre-existing conditions are excluded temporarily until the waiting period ends. |
| 27 | v2_policyholder_balances.csv | Indicates the maximum available benefit for each insured individual. |
Osigu's team can help you determine the best combination of files to suit your data model and operational needs.
Updated about 1 year ago